前面几篇教程主要记录了JS的一些基础内容,相对偏概念一些,从本篇开始的内容将更偏应用些,介绍基本DOM方法。
文档对象模型(DOM)是表示文档(HTML等)和访问、操作构成文档的各种元素的应用程序接口(与浏览器、平台、语言无关),它本质上是一个供程序和脚本动态访问或更新文档的文档平台。
基本DOM方法:
(1)直接引用结点
1、document.getElementByIdx_x_x(id)方法:在文档中通过id来查找结点元素,返回找到的结点对象(仅一个)。
2、document.getElementByTagName(tagName)方法:通过HTML的标签名(如p、div等)在文档中查找,返回满足条件的数组对象。
function start() {
myDocumentElements=document.getElementsByTagName_r("body");
myBody=myDocumentElements.item(0);
myBodyElements=myBody.getElementsByTagName_r("p");
myP=myBodyElements.item(1);
}
document.getElementsByTagName_r("body");中获取了文档中唯一的body元素。
document.getElementsByTagName_r("body");用于获取列表中的第一个元素,事实上列表中仅有一个body元素。
myBody.getElementsByTagName_r("p");获取了body元素中的p元素。
myBodyElements.item(1);从上一行返回的列表中取第二个对象,即body中的第二个p元素。
(2)简介引用结点
1、element.parentNode属性:引用父节点。
2、element.childNodes属性:返回所有子节点的对象数组。
3、element.nextSibling/element.nextPreviousSibling属性:引用下一个/上一个兄弟结点。
(3)获取结点信息
结点信息主要指结点名称、结点类型、结点值。
1、nodeName属性:获取结点名称。
2、nodeType属性:获取结点类型。
3、nodeValue属性:获取结点的值。
4、hasChildNodes():用于判断是否存在子节点。
5、tagName属性:获取标签名。
(4)处理结点信息
允许通过setAttribute()与getAttribute()方法设置/获取结点属性。
1、elementNode.setAttribute(attributeName,attributeValue):设置结点元素的属性。
2、elementNode.getAttribute(attributeName):获取属性值。
(5)处理文本结点
1、innerHTML属性:设置/返回结点开始和结束标签之间的HTML。
2、innerText属性:设置/返回结点开始和结束标签之间的文本。
(6)文档层级结构
1、document_createElement_x_x()方法:创建元素结点。
2、document_createTextNode()方法:创建文本结点。
3、a(childElement)方法:添加子节点。
4、insertBefore(newNode,refNode)方法:在refNode结点前插入newNode结点。
5、replaceChild(newNode,oldNode)方法:使用newNode取代oldNode结点。
6、cloneNode(includeChildren)方法:复制结点,includeChildren为bool,表示是否复制其子节点。
7、removeChild(childNode)方法:删除子节点。
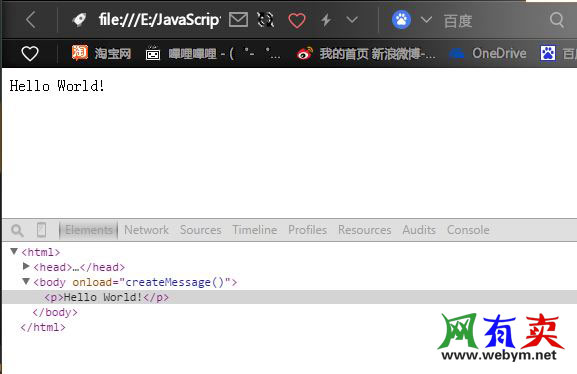
function createMessage() {
var oP = document_createElement_x_x("p");
var oText = document_createTextNode("Hello World!");
oP.a(oText);
document.body.a(oP);
}
上例中先创建了元素p和文本"Hello World!",然后通过a(childElement)方法,将文本附加在元素p上,最后将结点p附着在body元素(结点)上,效果如下图: