




SQLserver数据库的模糊查询有用like和charindex两种方法,很多人都纠结于这两种方法哪个效率高,小编今天就搭建实例,实际比较下。
test1表中有一千两百多万条数据,只给ID加了索引。
先看一下 '%我%'这种模糊查询:
declare @q datetime
set @q = getdate()
select ID,U_Name,U_Sex,U_Age,U_Address from test1 where U_Name like '%我%'
select [like执行花费时间(毫秒)]=datediff(ms,@q,getdate())
declare @w datetime
set @w = getdate()
select ID,U_Name,U_Sex,U_Age,U_Address from test1 where charindex('我',U_Name) >0
select [charindex执行花费时间(毫秒)]=datediff(ms,@w,getdate())
查询结果:
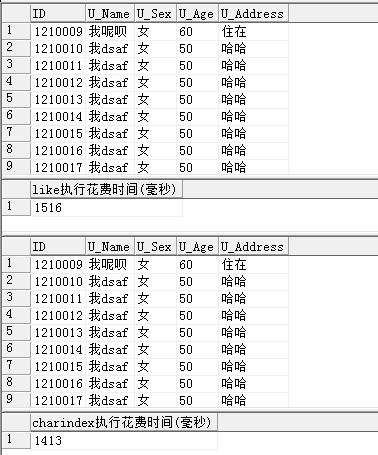
MS SQL的like和charindex查询效率的对比
两者的时间差不多,不过要是在千万、乃至上亿的数据中还是能明显感觉到两者的查询速度吧。
再看下'我%'这种的模糊查询:
declare @q datetime
set @q = getdate()
select ID,U_Name,U_Sex,U_Age,U_Address from test1 where U_Name like '我%'
select [like执行花费时间(毫秒)]=datediff(ms,@q,getdate())
declare @w datetime
set @w = getdate()
select ID,U_Name,U_Sex,U_Age,U_Address from test1 where charindex('我',U_Name) >0
select [charindex执行花费时间(毫秒)]=datediff(ms,@w,getdate())
查询结果:
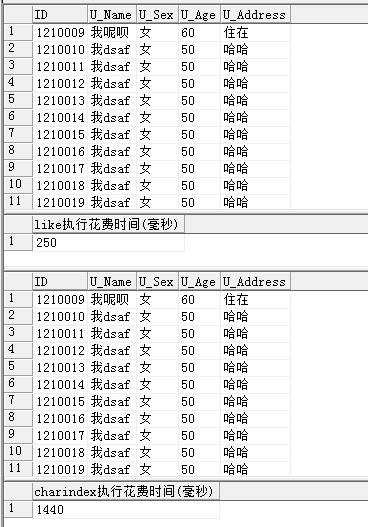
MS SQL的like和charindex查询效率的比较
所以需要在不同条件下选择两种模糊查询,'%我%'这种的就用charindex,'我%'这种的就用like!
声明:如需转载,请注明来源于www.webym.net并保留原文链接:http://www.webym.net/jiaocheng/1083.html
















